Research
Share Knowledge
Brainstorm Ideas
Achieve More

Research
Share Knowledge
Brainstorm Ideas
Self-healing infrastructure represents a fundamental shift from manual IT intervention to autonomous, AI-driven systems that detect, diagnose, and resolve failures without human intervention.
Unlike traditional monitoring that alerts teams after incidents occur, self-healing architectures predict anomalies and remediate them in real-time—often before users notice any degradation.
For C-suite leaders, this translates directly to protected revenue streams, reduced operational risk, and the ability to scale without linearly scaling IT headcount. Organizations implementing self-healing capabilities report 60-80% reductions in critical incidents and 40% lower infrastructure management costs within the first year.
Here's a question for every technology leader:
When your last critical system failure occurred, how long did it take from initial alert to full resolution—and what did that downtime cost in revenue, customer trust, and team burnout?
The reality is stark. According to Gartner, the average cost of IT downtime has reached $5,600 per minute, with enterprise organizations often losing $300,000+ per hour during outages. Yet 70% of organizations still rely on reactive incident response, in which human engineers diagnose and fix problems after they have already affected business operations.
This manual approach creates compounding C-level pain points:
Meanwhile, customer expectations for 99.99% uptime have become table stakes rather than differentiators. The convergence of AI/ML maturity, observability tooling, and infrastructure-as-code has created a tipping point. Self-healing is not futuristic—it is the competitive baseline for resilient enterprises.
Think of self-healing infrastructure as a digital immune system. Just as your body identifies and neutralizes threats without conscious effort, self-healing systems continuously monitor their own "health," automatically quarantine failing components, and deploy remediations—often rerouting traffic to healthy resources faster than a human could receive a pager alert.
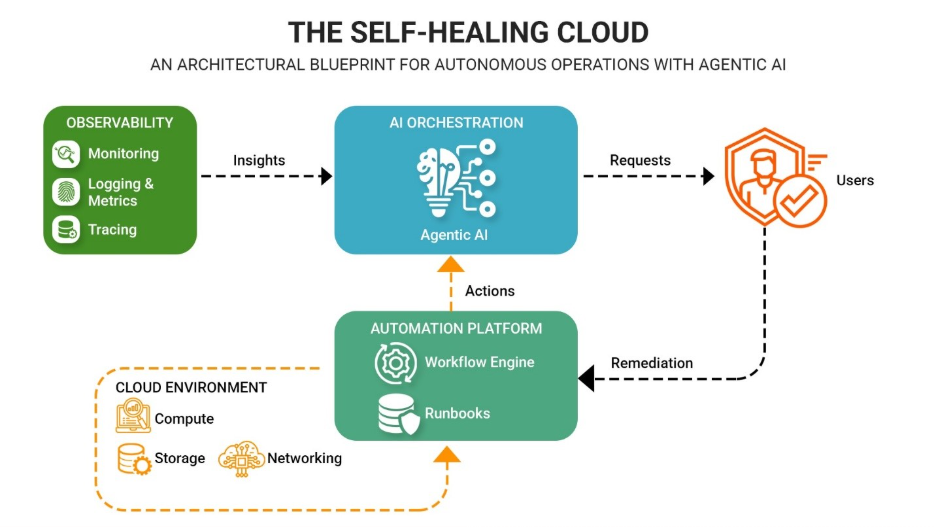
At its core, this involves three autonomous capabilities:
No manual ticketing. No 3 AM wake-up calls for routine failures. No cascading outages because the first alert went unnoticed for 15 minutes.
A global financial services firm implemented self-healing Kubernetes clusters that automatically isolate compromised containers and spin up sanitized replacements within 90 seconds.
The result → They reduced security incident containment time from 4 hours to under 2 minutes, cutting potential breach-related losses by an estimated $12M annually. The system also maintains immutable audit trails of every autonomous decision—satisfying regulators that governance is not sacrificed for speed.
A Fortune 500 retailer eliminated their "safety buffer" of 40% excess cloud capacity by deploying self-healing auto-scaling that predicts traffic spikes 15 minutes before they hit. Combined with automated failovers that reduced MTTR (Mean Time to Recovery) by 73%, they saved $4.2M in annual infrastructure costs while improving peak-season performance.
The CFO's summary: "We stopped paying for insurance we weren't sure worked and bought resilience that actually delivers."
A SaaS unicorn expanded into 12 new geographic markets without adding a single infrastructure engineer to its core team. Self-healing platforms managed the complexity of multi-region deployments, automated compliance adaptations for local data regulations, and ensured consistent 99.95% uptime across all markets.
The CTO noted: "We scaled our architecture faster than we scaled our headcount, that's how you maintain margins while growing aggressively."
Organizations implementing mature self-healing capabilities consistently report:
| Business Outcome | Typical Impact |
|---|---|
| Reduction in critical incidents | 60-80% within 12 months |
| Infrastructure cost optimization | 30-45% through rightsizing and reduced over-provisioning |
| Engineering productivity gain | 35-50% of team time redirected from incident response to innovation |
| Mean Time to Recovery (MTTR) | Sub-5 minutes for 90% of common failure scenarios |
| Compliance audit preparation | 70% faster through automated documentation and evidence collection |
Research on autonomous infrastructure adopters shows positive ROI typically achieved within 9–14 months, with 60–85% reductions in mean-time-to-recovery and 30% fewer production outages through intelligent self-healing capabilities.
Self-healing infrastructure does not emerge from purchasing a single tool—it requires intentional architectural foundations:
Comprehensive observability (metrics, logs, traces) is the prerequisite. You cannot heal what you cannot see.
Autonomous systems need guardrails. Define your "blast radius" policies upfront—which failures can be auto-remediated, which require human approval, and how financial exposure limits trigger escalation.
This shifts engineering roles from "operators" to "SRE architects" who design resilience patterns and refine ML models. Upskilling existing teams often outperforms external hiring for specialized autonomy engineers.
Start with non-critical workloads to build organizational trust in autonomous decision-making before applying to revenue-generating systems.
Executive hesitation often centers on control: If systems fix themselves, how do we ensure compliance, auditability, and accountability?
Modern self-healing platforms address this through:
The regulatory trajectory favors this approach: Regulators increasingly ask not, "Did humans approve of every change?" but "Can you demonstrate your controls operate consistently and are verifiable?" Self-healing systems often provide better audit trails than manual processes prone to documentation gaps.
Self-healing infrastructure is not about reducing headcounts, but about redeploying your most expensive talent from reactive maintenance to proactive innovation. In an era where digital uptime directly correlates with market valuation, autonomous resilience has shifted from a competitive advantage to an operational necessity.
Organizations that invest now in building self-healing capabilities will operate with fundamentally different economics: lower risk exposure, faster scaling trajectories, and engineering cultures focused on building rather than fixing. Those that delay will continue paying the hidden tax of manual operations—in downtime costs, talent attrition, and missed market opportunities.
ITPN helps enterprises architect, implement, and operationalize self-healing infrastructure at scale. Connect with our vetted network of site-reliability engineers, cloud architects, and AI/ML specialists to build a highly proficient team that shows ownership and delivers exceptional success consistently.
Get in touch with us today to access industry-standard knowledge assets such as solution accelerators, implementation frameworks, best practices, and more, completely for free.